 Node的简介与模块机制
Node的简介与模块机制
# Node的简介与模块机制
阅读《深入浅出Node.js》
# Node简介
# Node的由来
Node.js的作者是Ryan Dahl,是一名C/C++程序员,他发现高性能Web服务器主要有几个要点:事件驱动、非阻塞I/O。所以他最初的目的就是写一个基于事件驱动、非阻塞I/O的Web服务器,以达到更高的性能。
在实现Node时,Ryan Dahl评估过C、Lua、Haskell、Ruby等语言作为备选,结论为:C门槛过高,Lua自身存在许多阻塞I/O库,Haskell作者觉得自己不足以玩转,Ruby的虚拟机性能不好。相比之下,JavaScript比C的开发门槛低,比Lua的历史包袱少,又逢Chrome的V8引擎性能优秀。考虑到高性能、符合事件驱动、没有历史包袱,JavaScript成为了Node的实现语言。
Chrome浏览器和Node的组件构成如图。
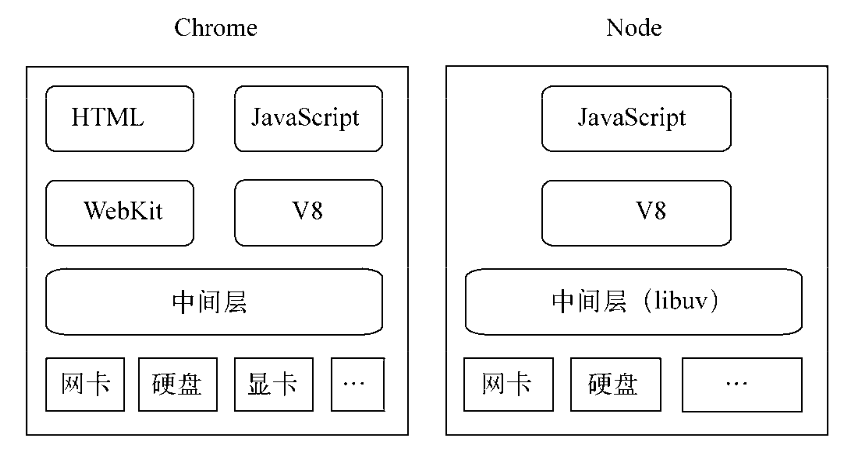
除了HTML、WebKit和显卡这些UI相关技术没有支持外,Node的结构与Chrome十分相似。他们都是基于事件驱动的异步架构,浏览器通过事件驱动来服务界面上的交互,Node通过事件驱动来服务I/O。
# Node的特点
# 异步I/O
异步调用中对于结果值的捕获符合Don`t call me, I will call you的原则,这也是注重结果,不关心过程的一种表现。经典的Ajax调用如下:
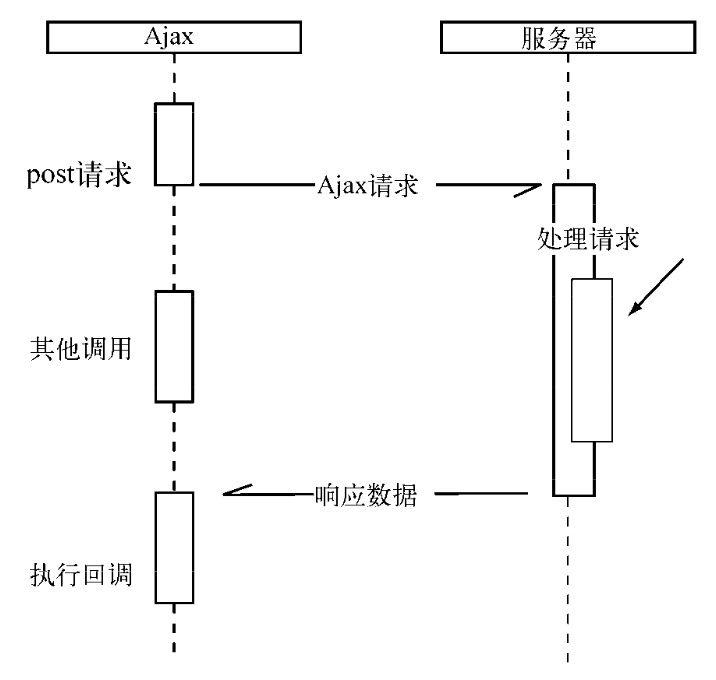
在Node中,异步I/O也很常见。与前端的Ajax调用方式类似:
'use strict'
const fs = require('fs');
fs.readFile('/path', (err, file) => {
console.log('读取文件完成');
});
console.log('发起读取文件');
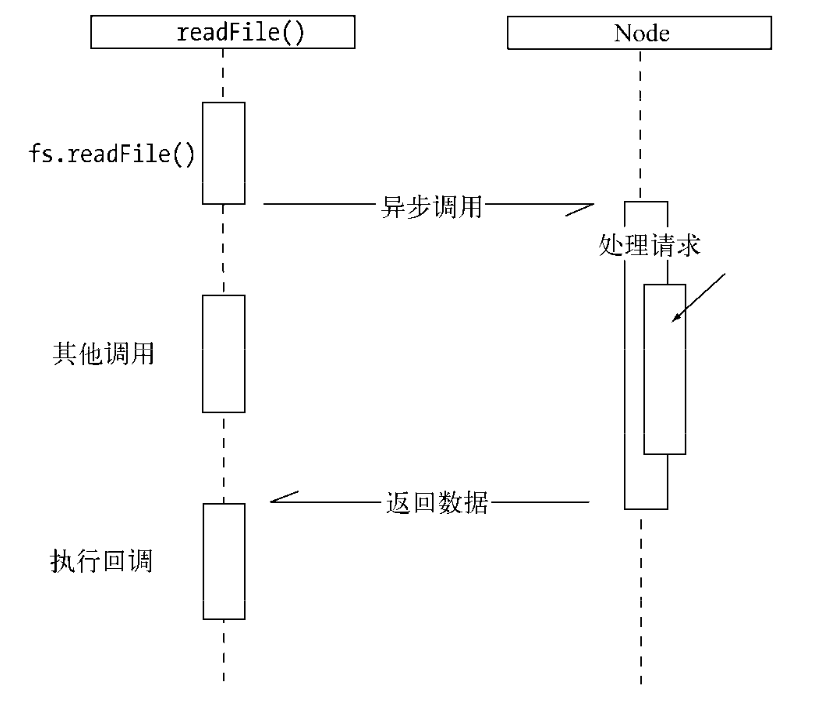
在Node中,绝大多数的操作都是以异步的方式进行调用。对于异步I/O,两个文件读取任务的耗时取决于最慢的那个文件读取耗时:
fs.readFile('/path1', function (err, file) { console.log('读取文件1完成');
});
fs.readFile('/path2', function (err, file) {
console.log('读取文件2完成');
});
对于同步I/O而言,他们的耗时是两个任务的耗时之和。
# 事件与回调函数
Node创建一个Web服务器,并侦听8080端口。对于服务器,我们为它绑定了request事件,对于请求对象,我们为它绑定了data和end事件:
const http = require('http');
// 服务器的request事件
http.createServer(function (req, res) {
const postData = ''; req.setEncoding('utf8');
// 请求的data事件
req.on('data', function (trunk) {
postData += trunk;
});
// 请求的end事件
req.on('end', function () {
res.end(postData);
});
}).listen(8080);
console.log('服务器启动完成');
事件的编程方式具有轻量级、松耦合、只关注事务点等优势;JS中回调函数无处不在,这是因为JS中,我们将函数作为第一等公民来对待,可以将函数作为对象传递给方法作为实参进行调用。
# 单线程
Node保持了JavaScript在浏览器中单线程的特点。在Node中,JavaScript与其余线程是无法共享任何状态的。
单线程的最大优点:不用像多想成那样处处在意状态的同步问题,没有思索的存在,也没有线程上下文交换所带来的性能上的开销。同样,缺点也存在:无法利用多核CPU;错误会引起整个应用退出,应用的健壮性值得考验;大量计算占用CPU导致无法继续调用异步I/O。
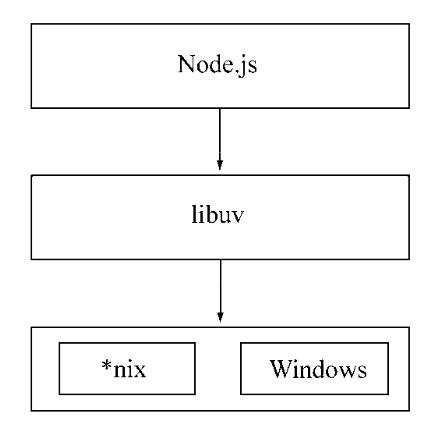
# 跨平台
Node兼容Windows和*nix平台主要得益于它在架构层面的改动,它在操作系统与Node上层模块系统之间构面了一层平台层架构,即libuv。Node基于libuv实现跨平台的架构如下图:
# Node模块机制
JavaScript先天缺乏一项功能:模块;在其他语言中,Java有类文件,Python有import机制,Ruby有require,PHP有include和require。在JavaScript发展过程中,社区为它指定了相应的规范,其中CommonJS规范的提出是非常重要的。
# CommonJS的出发点
CommonJS规范的提出,主要是为了弥补当前JavaScript应用中没有标准的缺陷,以达到像Python、Ruby和Java具备开发大型应用的基础能力,而不是停留在小脚本程序的阶段。
如今,CommonJS规范已初显成效,为JavaScript发展指明了一条非常棒的道路。这些规范涵盖了模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套接字、单元测试、Web服务器网关接口、包管理等。
Node与浏览器以及W3C组织、CommonJS组织、ESMAScript之间的关系如下图:
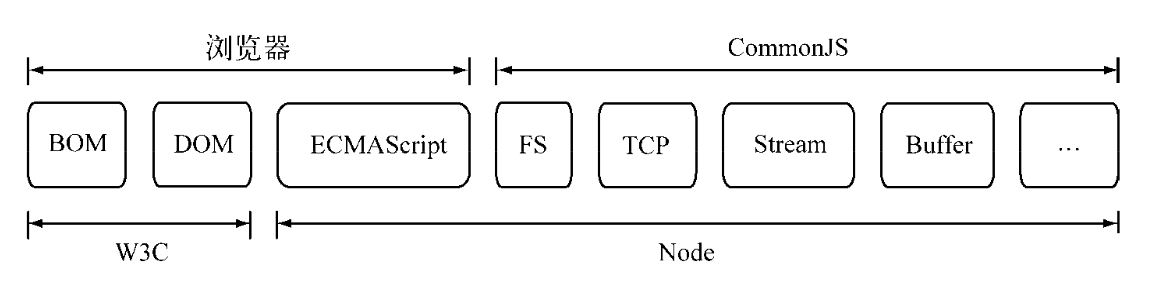
Node借鉴CommonJS的Module规范实现了一套非常易用的模块系统,NPM对Packages规范的完好支持使得Node应用在开发过程中事半功倍。
# CommonJS的模块规范
CommonJS对模块的定义十分简单,主要分为模块引用、模块定义和模块标识3个部分。
# 1.模块引用
模块引用的示例如下:
const math = require('math');
在CommonJS规范中,存在require()方法,这个方法接受模块标识,以此引用一个模块的API到当前上下文中。
# 2.模块定义
对应引入功能,上下文提供了exports对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个module对象,它代表模块自身,而exports是module的属性。在Node中,一个文件就是一个模块,将方法挂在在exports对象上作为属性即可定义导出的方式:
// math.js
exports.add = function () {
let sum = 0, i = 0,
args = arguments,
l = args.length;
while (i < l) {
sum += args[i++];
}
return sum;
};
在另一个文件中require()方法引入模块后,就能调用定义的属性和方法:
// program.js
const math = require('math');
exports.increment = function (val) {
return math.add(val, 1);
};
# 3.模块标识
模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命令的字符串,或者以.、..开头的相对路径,或者绝对路径。
模块的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。
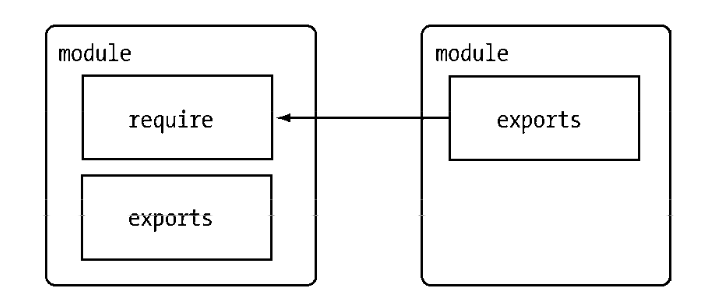
CommonJS构建的这套模块导出和引入机制使得用户完全不必考虑变量污染。
# Node的模块实现
Node在实现中并非完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。
在Node中引入模块要经历步骤:路径分析;文件定位;编译执行。
模块分为两类:一类是Node提供的模块,成为核心模块;另一类是用户编写的模块,称为文件模块。
- 核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件。在Node进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块被引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中优先判断,所以它的加载速度是最快的。
- 文件模块则是在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
# 模块加载过程
与前端浏览器会缓存静态脚本文件性能一样,Node对引入的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象。
不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式。不同的是核心模块的缓存检查先于文件模块的缓存检查。
# 路径分析
对于不同的标识符,即模块标识,模块的查找和定位有不同程度上的差异。
在Node的实现中,基于require()方法接受一个标识符作为参数进行模块查找。模块标识符查找主要分为以下几类:
- 核心模块,如
http、fs、path等。 .或..开始的相对路径文件模块。- 以
/开始的绝对路径文件模块。 - 非路径形式的文件模块,如自定义的
connect模块。
# 核心模块
核心模块的优先级仅次于缓存加载,它在Node的源代码编译过程中已经编译为二进制代码,其加载过程最快。
如果试图加载一个与核心模块标识符相同的自定义模块,是不会成功的。如果自己编写了一个http用户模块,想要加载成功,必须选择一个不同的标识符或者换用路径的方式。
# 路径形式的文件模块
以.、..和/开始的标识符,这里都被当做文件模块来处理。在分析路径模块时,require()方法会将路径转换为真实路径,并以真实路径作为索引,将编译执行后的结果放到缓存中,以使二次加载时更快。
由于文件模块给Node指明了确切的文件位置,所以在查找过程中可以节约大量时间,其加载速度慢于核心模块。
# 自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式。这类模块的查找是所有方式中最慢的一种。
模块路径
了解自定义模块前,首先要了解一下模块路径,模块路径是Node在定位文件模块的具体文件时指定的查找策略,具体表现为一个路径组成的数组。
路径的生成规则如下:
// 在任意一个文件中执行
console.log(module.paths);
得到如下结果:
[ '/Users/andy/Work/node/mcee_v2/platform/BulletAnt/node_modules', '/Users/andy/Work/node/mcee_v2/platform/node_modules',
'/Users/andy/Work/node/mcee_v2/node_modules',
'/Users/andy/Work/node/node_modules',
'/Users/andy/Work/node_modules',
'/Users/andy/node_modules',
'/Users/node_modules',
'/node_modules'
]
可以看出,模块路径的生成规则如下:
- 当前文件目录下的
node_modules目录。 - 父目录下的
node_modules目录。 - 父目录的父目录下的
node_modules目录。 - 沿路径向上逐级递归,直到根目录下的
node_modules目录。
它的生成方式与JavaScript的原型链或作用域链的查找方式十分类似。在加载过程中,Node会逐个尝试模块路径中的路径,直到找到目标文件位置。可以看出,当前文件的路径越深,模块查找耗时会越多,这是自定义模块的加载速度是最慢的原因。
# 文件定位
文件定位过程中,有一些细节要注意,主要包括文件扩展名的分析、目录和包的处理。
# 文件扩展名分析
require()在分析标识符过程中,会出现标识符中不包含文件扩展名的情况,这种情况下,Node会依次尝试.js、.json、.node的次序补足扩展名。
在尝试过程中,需要调用fs模块同步阻塞式地判断文件是否存在。因为Node是单线程的,所以这里是一个会引起性能问题的地方。
# 目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,这在引入自定义模块和逐个模块路径进行查找时经常会出现,此时Node会将目 录当做一个包来处理。
在这个过程中,Node对CommonJS包规范进行了一定程度的支持。首先,Node在当前目录下查找package.json (CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象, 从中取出main属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。 而如果main属性指定的文件名错误,或者压根没有package.json文件,Node会将index当做默 认文件名,然后依次查找index.js、index.json、index.node。
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完毕,依然没有查找到目标文件,则会拋出查找失败的异常。
# 模块编译
在Node中,每个文件模块都是一个对象,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if(parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。
对于不同的文件扩展名,其载入方法也有所不同,具体如下:
.js文件。通过fs模块同步读取文件后编译执行。.node文件。这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。.json文件。通过fs模块同步读取文件后,JSON.parse()解析返回结果。- 其余扩展名文件。都会被当做
.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
根据不同的文件扩展名,Node会调用不同的读取方式,如.json文件的调用如下:
// Native extension for .json
Module._extensions['.json'] = function (module, filename) {
var content = NativeModule.require('fs').readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
其中,Module._extensions会被赋值给require()的extensions属性,所以通过在代码中访问require.extensions可以知道系统中已有的扩展加载方式。
console.log(require.extensions); // { '.js': [Function], '.json': [Function], '.node': [Function] }
# JavaScript模块的编译
在CommonJs模块规范中,每个模块文件中都存在require、exports、module这3个变量,但是他们在模块文件中并没有定义,在Node的Api文档中,每个模块有__filename、__dirname这两个变量,他们从何而来?
事实上,在编译过程中,Node对获取的JavaScript文件内容进行了头尾包装。一个正常的JavaScript文件都会被包装成如下样子:
(function (exports, require, module, __filename, __dirname) {
var math = require('math');
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});
这样每个模块文件都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象。最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。
这就是这些变量并没有定义在每个模块文件中却存在的原因。在执行后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。
# C/C++模块的编译
Node调用process.dlopen()方法进行加载和执行。在Node的架构下,dlopen()方法在Windows和*nix平台下分别有不同的实现,通过libuv兼容层进行了封装。
实际上,.node的模块文件不需要编译,因为它是编写C/C++模块之后编译生成的,所以这里只有加载和执行的过程。在执行的过程中,模块的exports对象与.node模块产生联系,然后返回给调用者。
# JSON文件的编译
.josn文件的编译是3种编译方式中最简单的。Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋值给模块对象的exports,以供外部调用。
这里我们提到的模块编译都是指文件模块,即用户自己编写的模块。接下来介绍核心模块中的JavaScript模块和C/C++模块。
# 核心模块
核心模块分C/C++和JS编写的两部分,其中C/C++存放在Node项目的src目录下,JavaScript文件存放在lib目录下。
# JavaScript核心模块的编译过程
在编译所有C/C++文件之前,编译程序需要将所有的JavaScript模块文件编译为C/C++代码。此时并不是直接将其编译为可执行代码,要经过两步:
1. 转存为C/C++代码
Node才用了V8附带的js2c.py工具,将所有内置的JavaScript代码(src/node.js和lib/*.js)转换成C++里的数组,生成node_natives.h头文件,相关代码如下:
namespace node
{
const char node_native[] = {47, 47, ..};
const char dgram_native[] = {47, 47, ..};
const char console_native[] = {47, 47, ..};
const char buffer_native[] = {47, 47, ..};
const char querystring_native[] = {47, 47, ..};
const char punycode_native[] = {47, 42, ..};
...
struct _native
{
const char *name;
const char *source;
size_t source_len;
};
static const struct _native natives[] = {
{"node", node_native, sizeof(node_native) - 1},
{"dgram", dgram_native, sizeof(dgram_native) - 1},
...
};
}
在此过程中,JavaScript代码以字符串的形式存储在node命令空间中,是不可直接执行的。在启动Node进程时,JavaScript代码直接加载进内存中。在加载的构成中,JavaScript核心模块经历标识符分析后直接定位到内存中,比普通的文件模块从磁盘中一处一处查找要快很多。
2.编译JavaScript核心模块
lib目录下的所有模块文件也没有定义require、module、exports这些变量,在引入JavaScript核心模块的过程中,也经历了头尾包装的过程,然后才执行和导出了exports对象。
与文件模块有区别的地方在于:获取源代码的方式(核心模块是从内存中加载的)以及缓存执行结果的位置。
Javascript核心模块的定义如下:
function NativeModule(id) {
this.filename = id + '.js';
this.id = id;
this.exports = {};
this.loaded = false;
}
NativeModule._source = process.binding('natives'); NativeModule._cache = {};
源文件通过process.binding('natives')取出,编译成功的模块缓存到NativeModule._cache对象上。
# C/C++核心模块的编译过程
在核心模块中,有些模块全部由C/C++编写,有些则由C/C++完成核心部分,其他部分则由JavaScript实现包装或向外导出,以满足性能要求。后者是Node提高性能的常见方式。
这里将那些由纯C/C++编写的部分统一称为内建模块,因为它们通常不被用户直接调用。Node的buffer、crypto、evals、fs、os等模块都是部分通过C/C++编写的。
内建模块的优势在于:首先,它们本身由C/C++编写,性能优于脚本语言;其次,在进行文件编译时,它们被编译进二进制文件。一旦Node开始执行,它们直接被加载进内存中,无需再次标识符定位、文件定位、编译等过程,直接就可执行。
在Node的所有模块类型中,存在着一种依赖层级关系,即文件模块可能会依赖核心模块,核心模块可能会依赖内建模块。
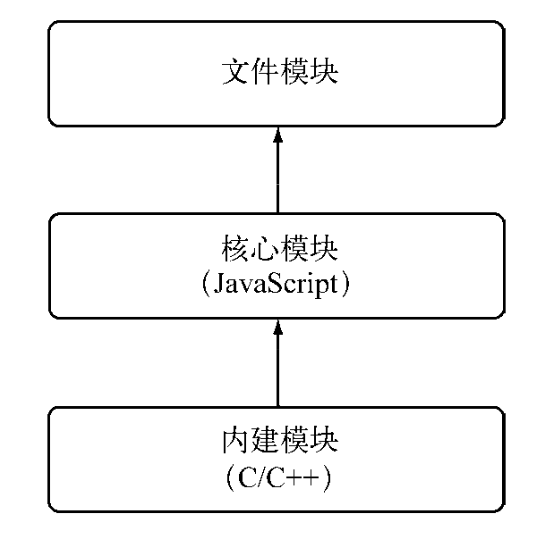
通常不推荐直接调用内建模块。如需调用,直接调用核心模块即可,因为核心模块基本都封装了内建模块。
内建模块将内部变量或方法导出,是如何做到的?
Node在启动时,会生成一个全局变量process,并提供Binding()方法来协助加载内建模块。Binding()的实现代码在src/node.cc中。
注:具体代码内容阅读《深入浅出Node.js》
# 核心模块的引入流程
如图是原生模块的引入流程,为符合CommonJS模块规范,从JavaScript到C/C++过程是相当复杂的,它要经历C/C++层面的内建模块定义、JavaScript核心模块的定义和引入以及(JavaScript)文件模块层面的引入。但对于用户来说,require()十分简洁友好。
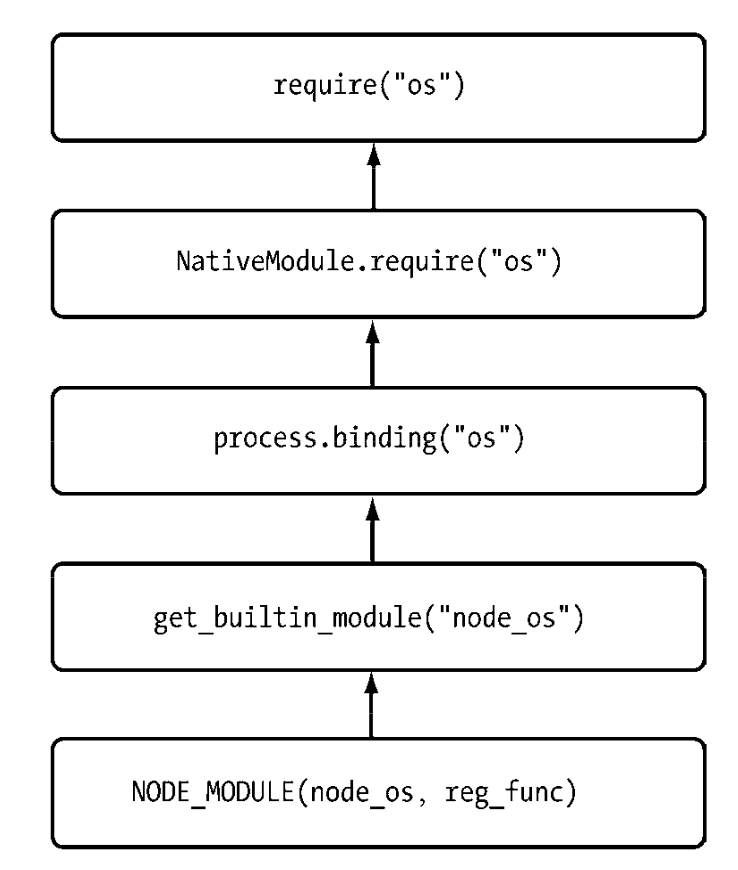
# C/C++扩展模块
P27
# 模块调用栈
文件模块、核心模块、内建模块、C/C++扩展模块之间的调用关系如图:
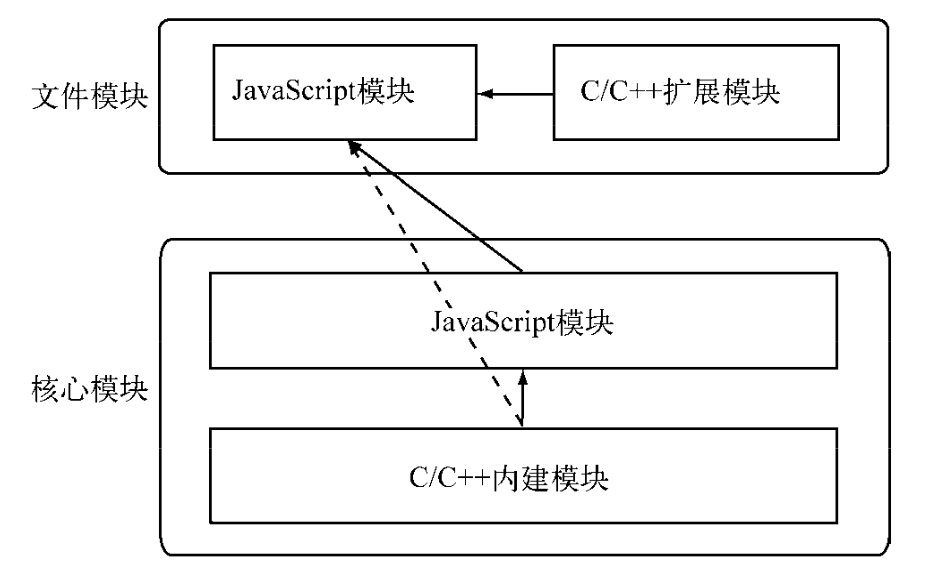
C/C++内建模块属于最底层的模块,它属于核心模块,主要提供API给JavaScript核心模块和第三方JavaScript文件模块调用。
JavaScript核心模块主要扮演的职责有两类:一类是作为C/C++内建模块的封装层和桥接层,供文件模块调用;一类是纯粹的功能模块,它不需要跟底层打交道,但又十分重要。
文件模块通常由第三方编写,包括JavaScript模块和C/C++扩展模块,主要调用方向为普通JavaScript模块调用扩展模块。